Keep track of what you've read online with remwharead
Today I’d like to talk to you about how I archive articles I read online and how I find them again.
I’ve found myself repeatedly in situations where I wanted to reference an article I knew I read, but couldn’t find it anymore. Be it that I didn’t remember the right search terms or that the article had gone offline. I searched for solutions to my problem, but could only find webservices, nothing that would allow me to keep an archive on my local computer. So I decided to fill that gap and write remwharead. It runs on Linux, probably BSD and maybe macOS.
What is remwharead?
remwharead is a tool that allows you to save URIs of things you want to remember in a local database, along with an URI to the archived version, the current date and time, title, description, the full text of the page and optional tags. You can then export all or a portion of your aggregated hyperlinks to different formats, including AsciiDoc, RSS, JSON and Netscape Bookmark File Format.
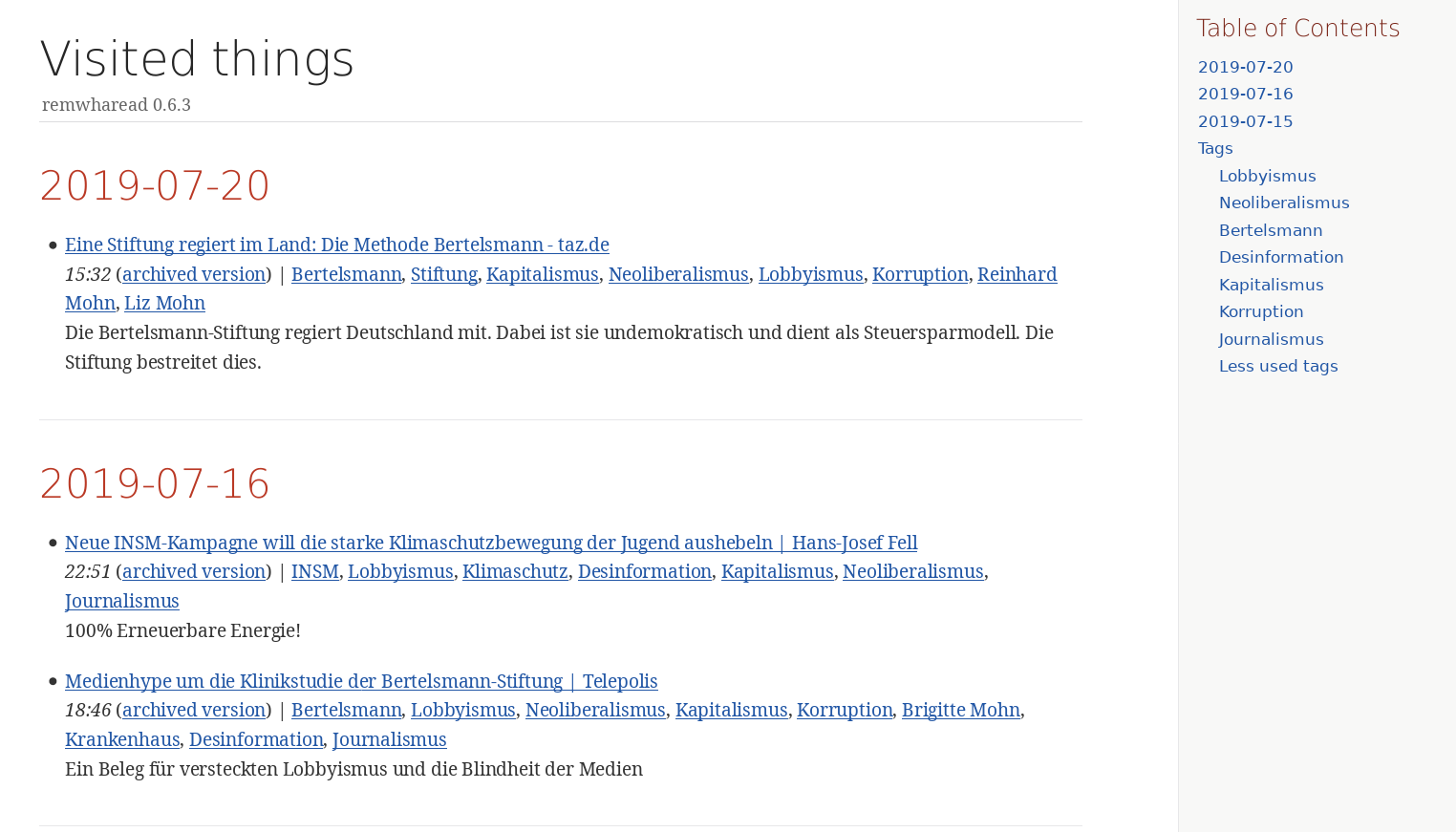
remwharead -e asciidoc | asciidoctor --backend=html5 -o file.html -Get remwharead
You can download the latest release from https://schlomp.space/tastytea/remwharead/releases. If your
CPU architecture is X86_64 (if you don’t know it probably is) and you use
Debian, Ubuntu, or a distribution based on Debian or Ubuntu, you can use the
attached .deb package. Download it and install with
apt install ./rewharead_*.deb. Gentoo users can use my repository as described
in the readme.
If there is no package for your distribution / operating system yet, you have to compile it yourself, as described in the readme.
The extension for Firefox is available from addons.mozilla.org.
How to use it
Adding an entry
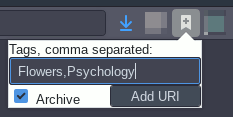
Saving things is simple: Just type remwharead followed by the URI into your
terminal and press “Enter”. To add tags, use the command-line switch -t or
--tags.
But most of the time you’ll probably want to use remwhareadFF, the Firefox extension.
remwharead -t remwharead,bookmarks,archive https://blog.tastytea.de/posts/keep-track-of-what-you-have-read-online-with-remwharead/remwharead will automatically ask the Wayback machine from the
Internet Archive to archive the page and store the URI to
the archived page, unless you run it with -N or --no-archive.
Retrieving / Exporting entries
To display the saved things using the export format “simple”, type
remwharead -e simple. You can filter by date and time with -T or
--time-span, filter by tags with -s or --search-tags and perform a
full-text search with -S or --search-all. You can also use --search-tags
and --search-all with regular expressions, with -r or
--regex.
% remwharead -e simple -T 2019-09-23,2019-09-24
2019-09-23: Keep track of what you've read online with remwharead
<https://blog.tastytea.de/posts/keep-track-of-what-you-have-read-online-with-remwharead/>
2019-09-23: Another good article
<https://example.com/good-article.html>Times are in the format YYYY-MM-DDThh:mm:ss. 2019-09-23 is short for
2019-09-23T00:00:00.
% remwharead -e simple -s "apple OR onion"
2019-08-03: The best onion soup recipe of the whole internet!
<https://example.com/onion-soup.html>
2019-04-12: 5 funny faces you can carve into YOUR apple today!
<https://example.com/apple-faces.html>Most export formats show only a portion of the available data for readability
reasons. If you want the full datasets, use -e json or -e csv. You can also
access the SQLite-database at ${XDG_DATA_HOME}/remwharead/database.sqlite, for
example with sqlitebrowser.
|
Note
|
${XDG_DATA_HOME} is usually ~/.local/share.
|
Create an RSS feed
Want to share what you read? with the “rss” export you can create an RSS feed for your friends to subscribe. Unfortunately remwharead can’t create a valid RSS feed out of the box, because it can’t know what content the “link”-element should have. You probably also want to change the title from “Visited things” to something more descriptive.
#!/bin/sh
remwharead -e rss -T $(date -d "-1 week" -I),$(date -Iminutes) \
| sed -e 's|<link/>|<link>https://example.com/</link>|' \
-e "s|<title>Visited things|<title>My hyperlink archive|" \
> /var/www/feed.rss|
Tip
|
Put that script into /etc/cron.hourly/ to update your feed once an hour.
|